After more than half of my life working with x86 architecture computers, I thought I already have seen most of what’s out there, until one day I stepped with a client that had one thing called, “THE MAINFRAME” in her Data Centre.
Back then I was an DevOps specialist in Test Automation and I was there, naive of me, to explain how could I help her to automate full manual testing operations performed over “THE MAINFRAME”. I was quite ready to have a discussion about how to rely on things like Cucumber, Selenium, Gatling, etc but I had no idea about the target system, I assumed it was a traditional x86 bunch of servers.
My surprised came when she started talking about z/OS, z.TPF, JCL, CICS, ZDEV0, LPARs and full list of acronyms that were totally alien to me.

If you haven’t ever worked with IBM Mainframes, you might be a bit lost like me, when someone talks to you about IBM Z, IBM Power Systems, LinuxOne, etc. In the end most of us just work daily with our shiny Macs, laptops or desktops and we access remotely fancy x86 VM machines running in some Cloud Data Centers.
Then you think, are Mainframes still that popular, are still needed, who on earth is still using them?
Reality is that today, behind the scenes, Mainframes are proccessing 300 Billion Transactions per day. Some comparative data: Google processes 3.5 Billion searches per day.
FACT: Did you know 92 of the top 100 banks in the world use the mainframe and they process 100% of all credit card transactions?
FACT: IBM Mainframes can run for 40 years, 24/7, without failing.
FACT: Nearly all Airline bookings are done on a Mainframe
FACT: 23 of the top 25 US retailers use Mainframe
FACT: 9 out of the top 10 insurance companies in the world use mainframe.
I’ve spent some time doing research to find out that, despite what some people claimed back in 2000ish, Mainframe is FAR AWAY from being dead, in fact, just the opposite.
This is why I decided to explore, learn and try to explain to fresh new mainframe ignorants like me, what IBM Mainframes are about.
A brief history of Mainframes
In 1950s IBM released the 700 series of Mainframes Vacuum Tube based Mainframes, with no OS installed on them. There were called the First Generation Mainframes.

A technologic jump happened when IBM moved into transistor based Mainframes, releasing the 7000 series. These were called the Second Generation Mainframes.

In 1964 IBM released the SYSTEM 360. It had an Operating System installed on it called OS/360. There were called the Third Generation of Mainframes and they would be the predecessor of the modern Z Series Mainframes. SYSTEM 360 was the way to standardise Hardware and Software for all the industries, as until then, each Mainframe was designed for a specific industry or scientific purpose and with no Operating System.

FACT: SYSTEM 360 IBM Mainframes were used in the NASA Apollo 11 mission.
Over the following years, SYSTEM 360 evolved until turning into z Series:
Year 1970: IBM launched SYSTEM 370
Year 1980: 3081, 3090, etc
Years 1990s: SYSTEM 390 comes up
Years 2000s: z Series appears
Just check this jaw dropping long list of mainframes.
In addition to the z Series Mainframes, in 2015 IBM released IBM LinuxONE, its first Linux based OS on the Mainframe.
Later in this article we will discuss about IBM Power Systems. Some people may think are Mainframes, but they are not, they are an inspired mid range enterprise machines/servers. In fact in the early days of Power, there was a PowerPC workstation and the microprocessor was also used in Apple Systems!
FACT: IBM Mainframes with 85-90% world market share is the leader.
That would put a bit of context, right?
In a nutshell
Mainframes: IBM Z family, IBM Linux One family
Mid range servers: IBM Power Systems
If you haven’t get lost at this point, you can continue, as things are getting more interesting now.
IBM Z History
IBM Z Mainframe History began in the 60s but we can find the Z branding around 1994 with the called z Systems and the introduction of CMOS technology.
zSystems were a Platform Independent IBM Mainframes that started on the zSeries 900 and were evolving and changing until what today we called the IBM Z
| IBM Z Mainframe Life Cycle History |
|---|
| z Systems –> zSeries 900 |
| z Systems –> zSeries 800 |
| z Systems –> zSeries 890 |
| z Systems –> System z9 EC |
| z Systems –> System z9 BC |
| z Systems –> System z10 EC |
| z Systems –> System z10 BC |
| z Systems –> zSeries 196 |
| z Systems –> zSeries 114 |
| z Systems –> zEnterprise EC12 |
| z Systems –> z13 |
| z Systems –> z13s |
| z Systems –> z14 |
| z Systems –> z14 ZR1 |
| z Systems –> z15 |
| z Systems –> z15 TO2 |

IBM Z Operating Systems
The OS by excellence in IBM Z is known as z/OS. Used by IBM zSeries Mainframes, it uses Job Control Language as the scripting language. At the contrary of general purpose computers and Operating Systems, Z has Operating Systems designed for specific purposes.
Before IBM Z, mainframes have been using OS/360 Family: ACP (Airline Control Program), DOS/360 (Disk Operating System), TSS/360 (Time Sharing System), CP/67 (Virtual Machine)
- z/OS: Unix System Services Operating System (2001), successor of the famous OS/360 which was born back in 1966. Several years and a dozen of evolutions after his birth OS/390 appeared in 1995, to finally getting consolidated in 2000 as z/OS.
- z/VM: Run thousands of Linux on Z virtual machines on one system. Evolved from the CP-40/CMS (1967) over 12 distributions in the VM line, to end up in z/VM in the year 2000. Later we will deep into how IBM became the father of Virtualization.
- z/VSE: Gain security and reliability for transactions and batch workloads. You probably have heard about its predecessors, DOS/360 or simply DOS? IT was the first of a sequence of operating systems for IBM System/360 and System/370. Back in time DOS/360 was the most widely used operating system in the world.
- z/TPF: specially aimed at transaction based business operations. It started in 1947 with ACP, to develop into TPF in 1979 and then z/TPF in 2005.
FACT: IBM Z systems are flexible and run z/OS, Linux, z/VSE, z/TPF and z/VM
As part of the Z Operating Systems, you can find some components like KVM, which is an open source hypervisor that allows us to run thousands of Linux on Z virtual machines on one system.
In terms of server virtualization we can find:
- LPAR Virtualization: Partition a physical server into logical partitions (LPARs) with protection certified to EAL5+.
- IBM Hypervisor (within z/VM).
- KVM
And of course, Linux! IBM Z supports distributions like Red Hat Enterprise, Suse Linux Enterprise and Ubuntu.
FACT: IBM z15 solutions are designed to deliver 99.99999% availability
Languages and technologies used in Mainframes
When using IBM Z mainframes, not Linux based, languages and technologies are not the same as the ones you can usually find in other architectures.
For example, the main scripting language we use in Mainframes is JCL (Job Control Language). Common application languages are COBOL, FORTRAN, C, C++, Java, REXX, etc.
You may heard about CICS (Customer Information Control System) which is used for online transactions. CICS is a family of mixed language application servers that works as a transaction engine on z/OS and z/VSE.
When you look into Databases, is pretty common to find DB2 and IMS.
And the more you dig the bigger is the number of tech you will find.
But, since we can run a Linux on a Mainframe, we can use any language 🙂
LinuxONE
LinuxONE (s390x) Servers were introduce in 2015, at the same time of IBM z13. Built on the IBM z14 mainframe and it’s z13 CPU, LinuxONE Emperor and the z12 processor based LinuxONE Rockhopper were launched during the LinuxCon.
FACT: Did you know that LinuxONE supports up to 8000 virtual machines with 32TB of memory and 170 dedicated processors?

LinuxONE was stated by IBM as the most secure Linux system ever with advanced encryption features built into both hardware and software, thanks to its dedicated crypto processors and cards. One of the main differences between Z and LinuxONE, is that the later was designed exclusively for the Linux operating system, including most commercial and open source Linux distributions.
IBM Z and LinuxONE platforms brought 20 years of open source software by the hand of Linux.

Of course LinuxONE has kept evolving fuelling digital transformations and journeys to secure hybrid cloud.
| IBM LinuxONE Mainframe Life Cycle LinuxONE history |
|---|
| LinuxONE Emperor |
| LinuxONE RockHopper |
| LinuxONE Emperor II |
| LinuxONE Rockhopper II |
| LinuxONE III |
| Linux ONE III LT2 |
IBM POWER SYSTEMS
First of all, what POWER means? Performance Optimization With Enhanced RISC
And what RISC means? Reduced Instruction Set Computer.
RISC is a computer with a small, highly optimized set of instructions, rather than the specialised ones found in CISC (Complex Instruction Set Computer).

IBM firs RISC system was designed in 1975, it was called IBM 801.
PowerPC 601 was the first generation of microprocessors to support 32-bit PowerPC instruction Set.
To understand the IBM Power Systems, you have to understand a bit more about what is “powering them up”, in this case are the IBM POWER microprocessors.
Do you remember “Deep Blue”? That supercomputer that won its first game against world champion Garry Kasparov playing chess? That was using a POWER2 microprocessor of 120 MHz.
Do you remember “IBM Watson” computer system wining on Jeopardy! tv program? It was built on IBM’s DeepQA technology and employed 90 IBM Power 750 servers, each of which used a 3.5GHz POWER7 eight-core processors. It could process 500 gigabytes per second.
IBM has a series of high-performance microprocessors called POWER, followed by a number designating generation. From POWER1 to what’s coming out today POWER10, here is a list of them:
| Name | Introduced | Clock |
|---|---|---|
| POWER1 | 1990 | 20-30 MHz |
| POWER2 | 1993 | 55-71.5 MHz |
| POWER3 | 1998 | 200–222 MHz |
| POWER4 | 2001 | 1–1.3 GHz |
| POWER5 | 2004 | 1.5–1.9 GHz |
| POWER6 | 2007 | 3.6–5 GHz |
| POWER7 | 2010 | 2.4–4.25 GHz |
| POWER8 | 2014 | 2.75–4.2 GHz |
| POWER9 | 2017 | ~4 GHz |
| POWER10 | coming soon |
Given we have explained what processors are powering up IBM Power Systems servers, let’s find out more about what you can find in its family.
IBM Power Systems has two predecessors, POWER and PowerPC hardware lines. PowerPC was the IBM’s response to the market trend of midrange computers. If you look back in time to 1991 you will find that the alliance AIM (Apple-IBM-Motorola) created PowerPC.
PowerPC was intended for personal computers and was used for 1994-2006 by lines like Apple’s Macintosh, iMac, iBook and PowerBook. After 2006, Apple migrated to Intel’s x86 architectures. If you want to become a bit more nostalgic you can also look at AmigaOne and AmigaOS 4 personal computers, that also used to use PowerPC.
The IBM Power Systems, are not workstations, is fine tuned high performing line of servers which appear in 2008 after merging the two lines of server and workstations under the same name, Power, later called Power Systems, initially powered by POWER6 architecture. PowerPC line was discontinued after this.

Those machines could be designed as Scale Out servers, Enterprise servers or High Performance Computing for example.
If you want to check out how a POWER9 based server from the family of Scale Out servers, you can check this out:
- Power Systems S924 – 4U, 2× POWER9 SMT8, 8–12 cores per processor, up to 4 TB DDR4 RAM, PowerVM running AIX/IBM i/Linux.
You can also find Enterprise servers:
- Power Systems E980 – 1–4× 4U, 4–16× POWER9 SMT8, 8–12 cores per processor, up to 64 TB buffered DDR4 RAM.
Or High performance computing servers:
- Power Systems S822LC for HPC “Minsky” – 2× POWER8+ SCM (8 or 10 cores), 2U. Up to four NVLinked Nvidia Tesla P100 GPUs and up to 1 TB commodity DDR4 RAM.
Depending on the IBM Power System model, you will find servers with more or less cores sizes and performance. For example, within the POWER6 range you can find:
- Blades (1-8 cores): JS22, JS12, 520, 550.
- Mid-range (4-16 cores): 570
- Enterprise (8-64 cores and up to 448): 595, 575
IBM Power Systems Operating Systems
In a nutshell, they run Linux, i for Business and AIX.
FACT: Did you know in 2020 IBM AIX remains as the #1 OS in the Unix market?
IBM AIX: An enterprise open standards-based UNIX made for Power Systems architecture.
IBM i: it runs on POWER system and supports older AS/400 workloads. Easily integrates with IoT, AI and Watson.
Haven’t your head blown up yet? Let me give you more as you probably have heard about systems such as AS/400, where this come from? Well, let’s check out the evolution of IBM i to find it out.
| System | Year |
|---|---|
| System/38 | 1978 |
| System/36 | 1983 |
| AS/400 | 1988 |
| IBM iSeries | 2000 |
| IBM Power Systems i for Business | 2008 |
| IBM Power9 i for Business | 2020 |
Within IBM Power we have seen introduced beautiful technologies, like the LPARs.
A logical partition (LPAR) is a subset of a computer’s hardware resources, virtualised as a separate computer. Logical partitioning divides hardware resources. Two LPARs may access memory from a common memory chip, provided that the ranges of addresses directly accessible to each do not overlap.
FACT: Did you know that IBM developed the concept of hypervisors (virtual machines in CP-40 and CP-67 by 1967) and in 1972 provided it for the S/370 as Virtual Machine Facility/370?
Yes IBM invented virtual machines, go and check in Wikipedia 🙂

LPAR (Logical Partitions was introduced in POWER4.
Dynamic Logical Partitions (DLPAR) was introduced not much after with the ability to move CPU, Memory and I/O slots/adapters between logical partitions while running in matter of seconds.
Later on Shared Processor Logical Partition were added, giving us the luxury of use discrete fractions of CPU cycles. Later Virtual I/O Server (VIOS) was introduced and eventually Micro-Partitions (Shared CPUs + Virtual I/O Server).
More recent technology is PowerVM, which runs i For Business, AIX and Linux over Power Hardware.
SUMMARISING
IBM Z today is pretty well recognised and well stablished in the market and today IBM Z is above the competition. Only IBM Z can encrypt 100% of application, database and cloud service data, while processing 30 billion transactions with 99.999% uptime.
On top of that IBM Z is built for cloud, ready for blockchain, optimized for machine learning, open for DevOps, and delivers 8.4x more effective security than x86.
IBM Power Systems keep providing cutting edge technologies and are the core of High-Performance Computing, Hybrid Cloud and Data and AI.
And just to add something to talk about in next articles, now we are coming with IBM Q to rule the Quantum world 🙂
So as I mentioned at the beginning of this article is far from being dead, it’s more alive than ever!
References
Mainframe: family tree and chronology
Power Systems for Enterprise Linux






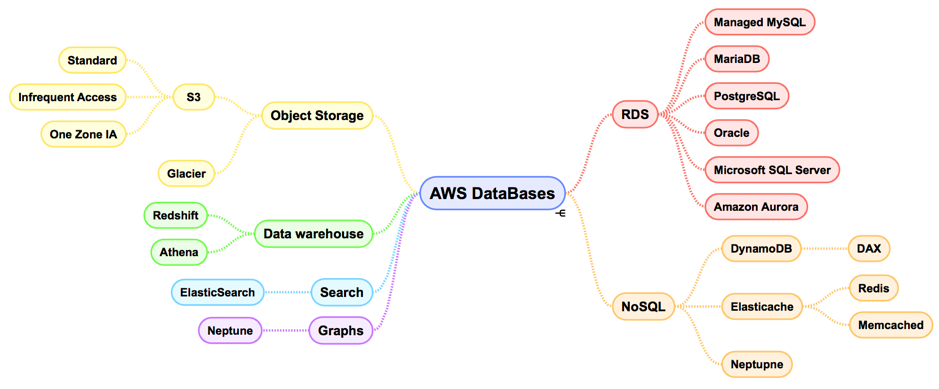




 extremely low cost but the minimum period of storage is 90 days.
extremely low cost but the minimum period of storage is 90 days. results are sent back to S3.
results are sent back to S3.













 The other one is the Tests Tab:
The other one is the Tests Tab:


 More information
More information