
Deciding what’s the right branching strategy can always be painful. From it, depends not only how your source code is being merged and maintained, but also how software is going to be built, tested, released and how hotfixes and patches are going to be applied.
Some teams go very ambitious and they start creating branches for everything: development, features, epics, releases, test, hotfixes and more.
The problem of this is not about the number of branches you use if as the team is disciplined enough and follows the agreed practices. The problem comes when the team changes quite often letting some practices to get missed or its not “forced” or “controlled” to follow those practices.
Some clear symptoms of bad branching management are:
• branches named out of the standards defined
• developers assigning their names to branches
• branches that can’t be tracked down to the user story were they belong to
• your main or development branch are behind the release branch
• the team is not branching out from the main or development branch when creating new features
• the production code is residing in a private branch
• the team has a branch per environment
• the branch name has a very long description such as: development-for-kafka-streams-api-october-work
• every time the team merges into development branch it takes hours if not days to resolve conflicts
• nobody knows exactly where the latest version of the code is
Some of these issues can be solved enforcing some branching rules in the Version Control Manager. We can protect the master branch from further commits unless these come from a pull request. At NTT Data we work a lot with Bitbucket, as it is one of the most popular Version Control Repositories based on GIT among our projects. Let’s check how this looks like on Bitbucket:

We can use prefixes on the feature branches by default so developers just have indicate the number of the user story that is related to.

Most of the VCMs nowadays have these options so, let’s talk now about branching strategy as having Source Code Version Control is kind of useless if you don’t have a proper branching strategy in your team.
Just Master
The simplest one is you have just a master branch and then create a feature branch every time we need to develop a new feature. Then we commit the code inside that private branch and when the code is tested and ready for release we merge it into the master branch through a pull request and after the approval from the reviewers.
At the end of the iteration the code is released into master.

Release Branches
Similar branching strategy is to have 2 branches, one for development and the other one for release, so then we can use the release branch for hosting the production code through proper labelling and we can create hotfixes from it.
At the same time, we are reducing the number of commits into the master branch, having a cleaner history.
Environments branches
Another approach to release branches is environment branches. With this model we are bringing visibility to what’s deployed on each environment, facilitating rollbacks and development of hot-fixes on the spot.
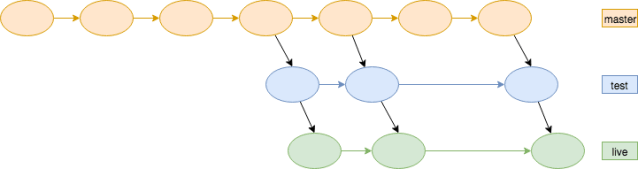
Feature branches
I’m a big fan of feature branches, as soon as they are short living, as they can be very noisy, specially if we treat feature branches as user stories on our sprint. But in other hand can be very useful to isolate features and for testing them independently. One of the downsides is that the integration can be painful, but you can always opt for techniques such as feature toggling on your production version (main).


Gitflow
The overall flow of Gitflow is:
- A
developbranch is created frommaster - A
releasebranch is created fromdevelop Featurebranches are created fromdevelop- When a
featureis complete it is merged into thedevelopbranch - When the
releasebranch is done it is merged intodevelopandmaster - If an issue in
masteris detected ahotfixbranch is created frommaster - Once the
hotfixis complete it is merged to bothdevelopandmaster

This model can be quite complex to understand and to manage, specially if the branches are living too long or if we are not refreshing our branches periodically or when needed.
Also as you can appreciate, master = production, which means is the main player here. Hotfixes are branched off from master and merged back into master.
Develop is merged into a release branch which eventually is used for release prep and wrap up and then merged into master.
In the end, master contains the releasable version of your code, where should be tagged properly, and the number of branches we have behind it, despite they can be overwhelming, help us to move the code through the different stages of the software development so we can refine it and debug it in a more sequential manner than with GitHub Flow.
The downside of this is that the team can struggle with too many branches and it has to be very disciplined when using Gitflow as they can easily lost track of the code state, have branches way behind master, merging can be a nightmare sometimes and you can end up easily with a list of 50 branches open at different stages of development which can make the situation unmanageable.
Github flow:
One of the favourite branching strategies by the developer community is the Github flow approach. This approach it looks simple but it is difficult to achieve if you want to get the maximum potential out of it.
Within this branching model, the code in the master branch is always in deployable state, it means that any commit into the master branch represents a fully functional product.
The basic steps are:
- Create a branch
- Add commits
- Open a pull request
- Discuss and review the code
- Deploy into production environments (or others) for testing
- Merge into master
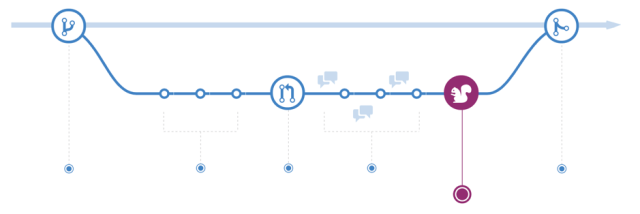
The recommendations using this model are:
- Try to minimise the number of branches
- Predict release dependencies
- Do merges regularly
- Think about the impact of the choice of repository
- Coordinate changes of shared components
One thing that we should do to ensure the code is master is always in deployable state is to run the pertinent functional or non functional tests at the branch level, before we merge into master. With this we can ensure that the quality of the code that goes into master is always good and is fully tested.
Some teams follow this to the point of even deploy into production straight from the feature branch, before the merge happens and after the tests have passed and, if something goes wrong, rollback deploying the code that is in the master branch again.
This model is basically encouraging Continuous Delivery.
Summary
After many years and many types of projects (apps, websites, databases, AI, infrastructure, dashboards, etc), I have come with three advices:
a) Analyse how the development team work and come with a model that adapts to them and not the opposite. I have seen many teams being forced to use GitFlow, and then spend months trying to fix the chaos created in the repo as they quite didn’t understand it or didn’t adapt to the way the release code.
b) Keep it simple and work with the team to become more mature and agile when releasing software. There is nothing wrong with starting a project just with a master branch and deal with that for a while until the team feels confident enough to start working with multiple branches. If they are scared about working straight against a master branch, just create a basic model of development-master branches and just do merges all together once in a sprint into master so the team can review the whole process.
Believe or not, there are many teams out there that still don’t work with branching or git! So introducing a full GitFlow concept for the first time to these teams can be overwhelming.
c) If after few sprints, you feel the model you use it’s not working for you try something different, don’t be shy. In our DevOps Squad at NTT Data we do DevOps Assessments where we also define and implement with you the branching strategy that could fit better to your team given the nature of your projects and your way of working.
If you ask me for my favourite, GitHub flow is the one. But it requires a good level of maturity when it comes to quality control and you have to make sure that all the environments and testing are ready and can be triggered at branch level, which requires some degree of automation.
In one of the projects I have recently worked on at NTT Data, we used to capture the Pull Request from Bitbucket with a hook in Jenkins, then build the code, deploy dynamically and environment on Azure using Terraform and Ansible, then run functional and non functional tests and if the build/deploy pipeline is green, then merge and close the Pull request.
There is a nice integration between Bitbucket and other DevOps tools that can help you to achieve this level of automation and branching strategy.
I hope you come up with the right one for you!
Happy branching.
References:
Feature isolation: https://docs.microsoft.com/en-us/azure/devops/articles/effective-feature-isolation-on-tfvc?view=vsts
Github flow: https://guides.github.com/introduction/flow/
Bitbucket and NTT Data: https://uk.nttdata.com/News/2019/03/NTT-DATA-UK-Becomes-Atlassian-Gold-Partner
